LLM inference is the process in which a large language model uses its learned parameters to generate a response based on new input text. The model receives a prompt, converts it into tokens, analyzes the context through multiple transformer layers, and predicts the next word step by step. This sequence of computations is the very moment when the model “thinks” in real time.
During inference, no learning or parameter updates occur — the model simply applies its fixed weights to produce output. Every answer you see from ChatGPT, Claude, or Llama is the result of billions of GPU computations executed in fractions of a second.
At times, it feels as though the model is creating in a stream of thought, like a poet who doesn’t recall but simply speaks. Yet behind that apparent spontaneity lies the cold precision of mathematics — it doesn’t imagine, it calculates. And still, in this intersection between algorithm and meaning, something emerges that we intuitively call intelligence.
This phase is the heartbeat of any LLM system — the point where data and probabilities transform into coherent, meaningful language.
What Is Inference in Machine Learning?
When we talk about inference in machine learning, we refer to the moment when a model starts acting — using what it has already learned to make predictions and produce results. If the training phase is about acquiring knowledge, inference is about applying that knowledge in the real world. The model no longer learns — it executes: it takes input, processes it through its internal parameters, and returns a prediction.
From a technical standpoint, this is simply a forward pass through the neural network — the data flows through trained weights without any backward updates.
The concept is easiest to grasp with a language model. When you type “The cat is…”, the model instantly evaluates the probabilities of possible continuations — “sleeping,” “on the table,” “playing with a toy” — and selects the most likely one. That operation is inference — the application of learned patterns to new data.
In machine learning, inference always follows training. It’s the stage where the model demonstrates that it has truly internalized patterns — and can now use them to generate text, recognize images, or perform any other task it was trained for.
What Does LLM Inference Mean?
LLM inference is the stage where a large language model takes a text prompt and turns it into a response — one token at a time.
Each answer from GPT-4, Claude, or Llama is the outcome of a precise sequence of computations, where every new token depends on all that came before.
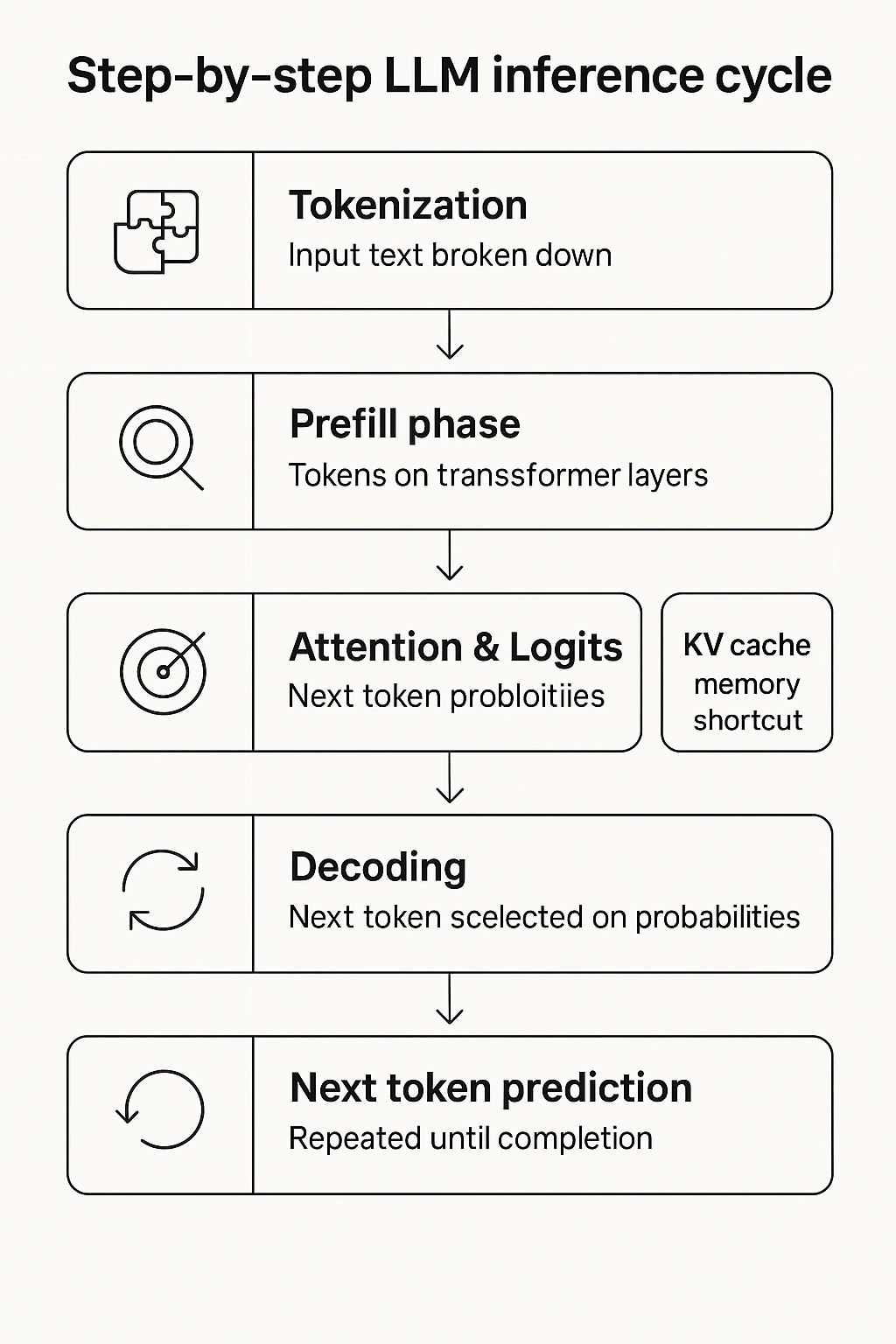
The process begins with a prompt sent by the user and unfolds through a series of steps:
- Tokenization. The input text is broken down into tokens — small fragments of words or symbols that the model can understand.
- Prefill phase. All tokens pass through the transformer layers as the model analyzes context and builds an internal representation of meaning.
- Attention and logits. The attention mechanism determines which parts of the text are most relevant and computes probabilities for every possible next token.
- Decoding. Based on these probabilities, the model selects the next token — either deterministically (greedy decoding) or with controlled randomness (temperature or nucleus sampling) — and appends it to the output sequence.
- Next-token prediction. The process repeats until completion. To speed up computation, the model stores intermediate results in the KV cache, avoiding redundant recalculations of attention.
All of this happens in milliseconds. At no point does the model learn — it simply applies the statistical patterns it has already internalized, turning probabilities into coherent text. And while beneath the surface it’s just math, GPUs, and matrix multiplications, from the outside it feels like something more: a machine that keeps a thought going.
Read also about
Self-Hosted LLMs in 2026
How LLM Inference Works Step by Step
The LLM inference process can be seen as a sequence of steps that the model goes through each time it generates a response. Inside, there are millions of matrix operations, yet the logic remains consistent and easy to follow.
🧩 1. Input processing (tokenization)
The model receives an input — the prompt — and breaks it down into tokens, small fragments of words or symbols.
For example, “The cat sleeps” might be represented as a sequence of numbers like [1012, 2305, 4512].
This allows the model to work not with words, but with numerical vectors that capture meaning.
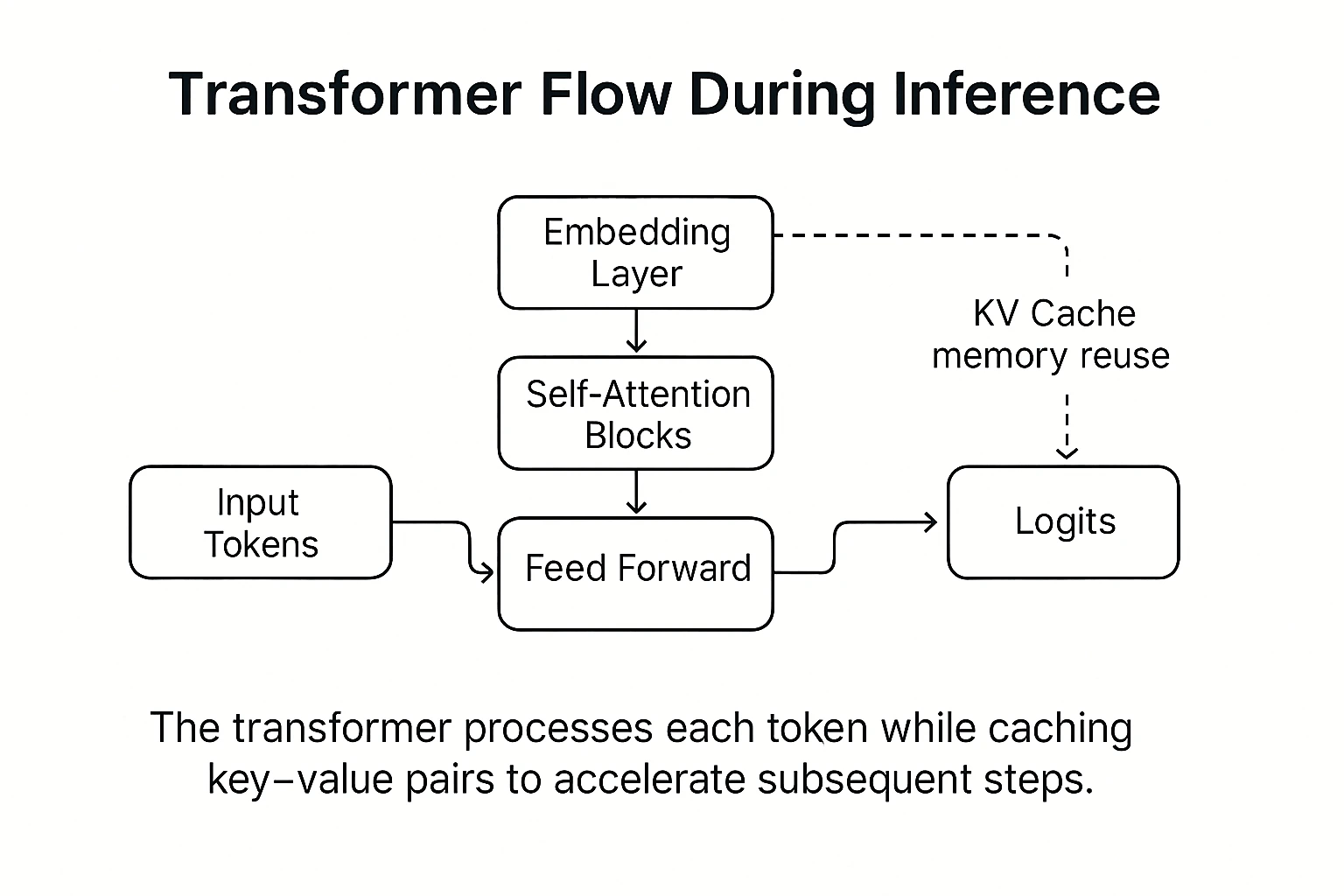
⚙️ 2. Prefill phase — forward pass through transformer layers
During the prefill stage, the entire input passes through the transformer layers.
The model analyzes tokens in parallel, building an internal representation of context — a kind of semantic map. This is the classic forward pass: data flows through trained weights without any backpropagation or parameter updates.
🔍 3. Decode phase — attention and probabilities
Once the context is prepared, the decode phase begins. The attention mechanism determines which parts of the input are most relevant for the next step, and the model computes probabilities (logits) for each possible next token. To speed up the process, it uses a KV cache — memory that stores results from previous steps,
allowing the model to reuse attention data instead of recalculating it each time.
🎯 4. Selecting the next token
The model chooses the next token based on these probabilities. Sometimes it picks the most likely option (greedy decoding), other times it adds controlled randomness (temperature, top-p sampling). The decoding method directly affects the text’s style — from precise and factual to more natural and creative.
🔁 5. Repeating until completion
The selected token is appended to the already generated text, and the entire inference cycle repeats — token by token — until the sequence ends or reaches the maximum length.
From the outside, it looks like the model is simply “writing text,” but under the hood, a complex transformer architecture is at work — thousands of layers analyzing context, computing probabilities, and turning mathematics into coherent speech.
Why LLM Inference Is Challenging
Many people think that LLM inference is simply about generating text. In reality, what happens under the hood is a computational factory — billions of matrix operations executed every second just to predict the next word with the right probability.
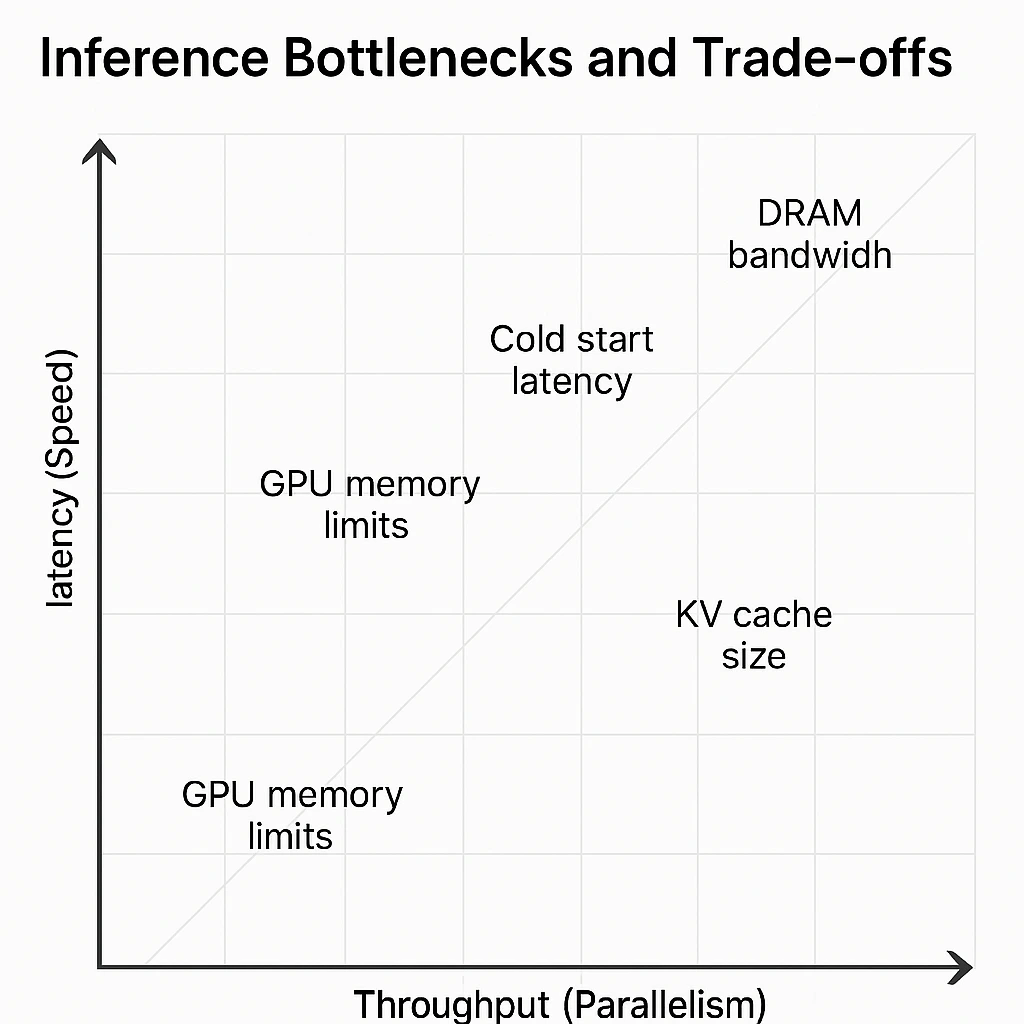
The larger the model, the heavier this process becomes. A model with 70 billion parameters activates tens of gigabytes of weights and keeps intermediate states (KV cache) directly in GPU memory. If the data doesn’t fit and spills to disk, everything slows down — latency increases and the cost of inference rises.
Each token requires a full forward pass through all transformer layers. Even on modern GPUs, this takes around 1–3 milliseconds per token — which means that long answers quickly add up to several seconds of generation time. Another common bottleneck is cold start latency, when the model is first loaded into memory — that’s why cloud APIs sometimes feel like they “hesitate” before generating the first response.
Beyond latency, there’s also throughput — how many tokens or requests the system can process simultaneously. Even a fast model can stall if GPU memory runs out or the hardware can’t handle parallel workloads.
The main bottlenecks in inference are DRAM bandwidth, GPU memory capacity, and I/O operations.
When memory can’t keep up with computation, much of the GPU sits idle.
Ultimately, LLM inference is a balance between speed, quality, and cost. Tuning the right configuration is like conducting an orchestra — every component must stay in sync. Understanding these constraints is essential for anyone building LLM-based systems, because “asking a model a question” actually means triggering one of the most complex engineering mechanisms ever created.

Real-World Examples of LLM Inference
To understand how LLM inference works in the real world, you only need to look at the tools we use every day. Every response they produce is the result of that same token-by-token generation process described earlier.
💬 Real-time inference — ChatGPT, Claude, Gemini
When you type a message into ChatGPT or Claude, inference happens in real time. The model receives the prompt, processes it across distributed GPU clusters, and streams back text token by token. Each reply feels instantaneous, but behind the scenes are hundreds of servers, load balancing, caching, and streaming pipelines — all working together to support millions of sessions with just a few milliseconds of delay.
💻 On-device inference — Llama.cpp, Ollama, GPT4All
Here, everything runs locally — on your laptop, personal server, or even a smartphone. These models are smaller and less capable, but they offer full autonomy and privacy: no cloud, no data sharing. On-device inference is popular for offline chatbots, personal assistants, and edge applications where connectivity and privacy matter.
☁️ Cloud API inference — OpenAI, Anthropic, AWS Bedrock
Most companies rely on this approach. When you call the OpenAI or Anthropic API, inference happens on their infrastructure — in massive data centers optimized for AI workloads. You send a request and receive a ready-made response without worrying about VRAM, model loading, or scaling. This is the dominant form of LLM deployment in production systems, where reliability and throughput are critical.
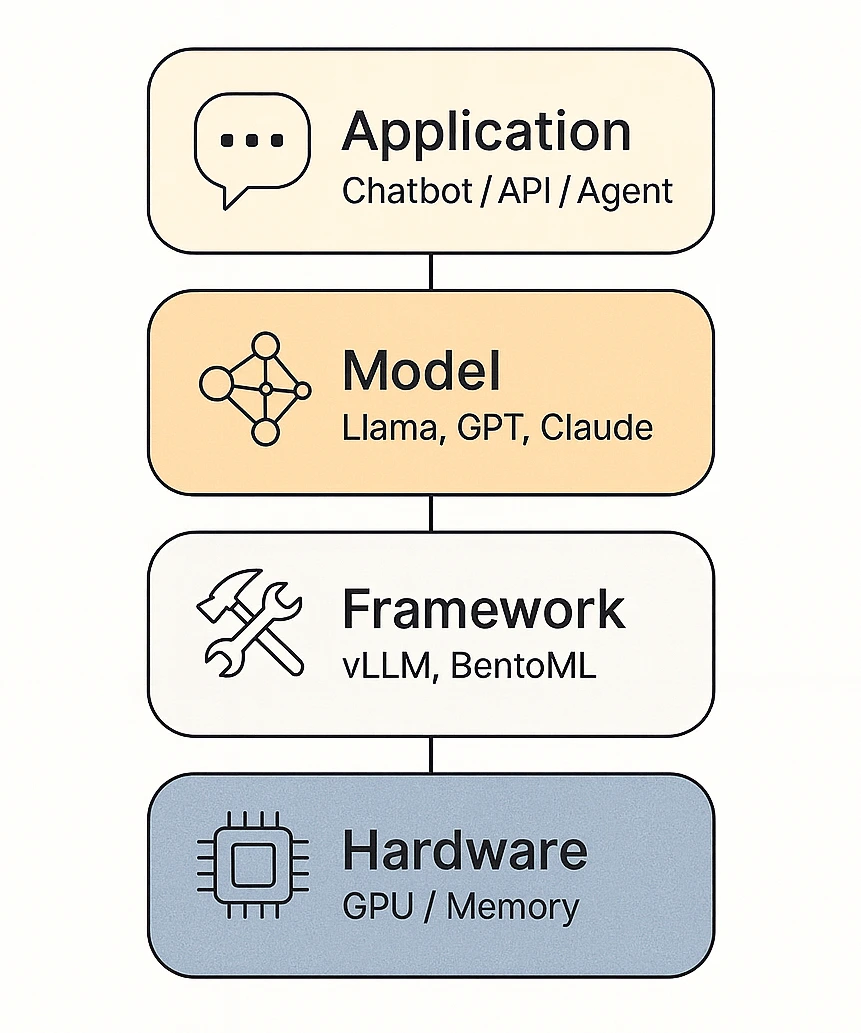
🧠 Framework-based inference — vLLM, BentoML, SGLang
For large-scale or production environments, engineers use specialized frameworks designed for performance and stability:
- vLLM — maximized throughput and streaming efficiency
- BentoML (OpenLLM) — enterprise and API-ready deployments
- SGLang — flexible for custom or multimodal agents
- Ollama / llama.cpp — for local or hybrid setups
Each framework serves a specific purpose — some prioritize speed, others simplicity or control.
📊 Types of LLM Inference Deployment
| Type | Where it runs | Examples | Advantages | Limitations |
| Real-time inference | Cloud | ChatGPT, Claude, Gemini | Instant responses, scalability | Cost, network latency |
| On-device inference | Local device / server | Llama.cpp, Ollama | Privacy, offline mode | Limited resources |
| Cloud API inference | Cloud services / APIs | OpenAI, Anthropic, AWS | Easy integration, reliability | Cost, vendor dependency |
| Framework-based | Cloud / hybrid | vLLM, BentoML, SGLang | Speed, scalability | Complex setup |
All these methods are layers of the same ecosystem. Real-time inference enables instant interaction,
on-device inference ensures autonomy, and cloud or framework-based deployments bring scale and stability. Together, they form the infrastructure that makes LLMs truly practical — from personal laptops to enterprise-grade AI systems.
Read also about
AI Agent Frameworks
Summary & Key Takeaways
- LLM inference is the moment when a large language model applies everything it has already learned to generate text, code, or answers. It’s not training — it’s pure execution: using existing knowledge in real time to turn input into meaningful output.
- Behind every response lies a complex inference process — tokenization, transformer layer passes, probability calculations, and next-token selection. Billions of computations unfold behind every second of text generation.
- Inference demands enormous resources — from high-performance GPUs to optimized pipelines and memory caches. That’s why latency, generation speed, and cost of inference are key metrics when working with large models.
- Understanding how LLM inference works helps design better infrastructure and LLM deployment strategies: choosing the right frameworks (vLLM, BentoML, Ollama) and balancing speed, quality, and cost.
- The next step is inference optimization — making generation faster, cheaper, and more efficient without sacrificing quality. That’s the path toward building scalable, accessible, and truly intelligent AI systems.
FAQ
What is LLM inference?
LLM inference is the process by which a large language model (LLM) applies its learned patterns to generate text, code, or other outputs. Every time you enter a prompt and receive a response, the model performs inference — predicting the next token step by step using its parameters and context.
How is inference different from training?
During training, the model learns from large datasets and updates its parameters. During inference, those weights are fixed — the model no longer learns but instead uses its acquired knowledge to produce coherent and meaningful output.
Why is inference expensive?
Inference is computationally intensive. Each token is generated through a full forward pass across the transformer layers, which consumes GPU memory and power. Larger models increase latency and cost of inference, meaning even short responses can require billions of operations — and cost real money in compute time.
What are examples of LLM inference?
- Real-time inference: ChatGPT, Claude, Gemini — cloud-based models generating responses instantly.
- On-device inference: local model execution using tools like Llama.cpp, Ollama, or GPT4All.
- Cloud API inference: large-scale API services such as OpenAI, Anthropic, or AWS Bedrock that handle inference remotely.
Can you run inference locally?
Yes. Modern frameworks allow on-device inference without any cloud dependency. Tools like Llama.cpp, Ollama, and MLC-LLM let you run models directly on your laptop or local server — trading some speed for privacy and full control.

Alex Grim
I’m an independent developer and AI automation specialist focused on building practical systems for content and SEO.
Over the past years, I’ve worked with WordPress, n8n, and AI tools to help creators and teams save time and scale their work efficiently.
Here I share insights, frameworks, and workflows for turning AI into a productive part of everyday operations.

